
Violazioni di dati personali, tra rischi e investimenti
A cura di Redazione Selefor CReFIS
La penetrazione delle tecnologie digitali nelle attività di famiglie, imprese e pubbliche amministrazioni implica la codifica di tali attività in dati che vengono elaborati per il perseguimento delle rispettive finalità. In questa prospettiva, i processi di funzionamento di un paese integrano trattamenti di grandi quantità di risorse informative, in tal modo delineando un nuovo modello socioeconomico di cui vengono esaltate, principalmente dagli economisti, l’efficacia e l’efficienza.
D’altro canto, la crescente dipendenza dalle tecnologie e dalle rappresentazioni informative che queste producono ha ampliato le occasioni di violazione per cui le organizzazioni e le persone sono esposte a rischi riguardanti diritti, libertà e legittimi interessi. Incidenti come quello che ha coinvolto la Regione Lazio nell’agosto 2021 sono chiari esempi di come una violazione della sicurezza informatica – nel caso specifico una indisponibilità di servizi e dati – possa produrre ricadute sugli interessati. Nel caso specifico l’indisponibilità ha riguardato dati relativi alle prenotazioni per la somministrazione dei vaccini con conseguenti disagi per le persone interessate rappresentati, tra gli altri, dall’inevitabile rinvio della somministrazione e del rilascio della relativa certificazione.
Questo e altri casi mettono in luce anche il mancato adeguamento delle organizzazioni alle norme previste dal regolamento europeo relativo alla protezione dei dati personali che contemplano, tra gli altri obblighi, l’adozione di misure tecnologiche e organizzative idonee a prevenire le minacce che possano determinare, ad esempio, la loro distruzione, perdita o divulgazione non autorizzata e, se del caso, anche misure correttive per porre rimedio alle violazioni che si sono comunque verificate.
I soggetti pubblici e privati sono pertanto chiamati a organizzarsi e ad investire nella sicurezza dei trattamenti di dati personali. Ma sono proprio gli investimenti a rappresentare la nota dolente delle politiche di sicurezza, specie nelle realtà di piccole dimensioni dove tali investimenti trovano poco spazio sia per ragioni di limitata disponibilità di risorse economiche sia perché i manager tendono a considerarli solo un un flusso di cassa in uscita senza una prospettiva di rendimento. Prospettiva che, invece, esiste ed è rappresentata dai “costi evitati” e da altri “benefici intangibili” (accessori, supplementari) che, nel medio-lungo periodo, sono superiori agli investimenti in sicurezza richiesti. Tuttavia, per comprendere il ritorno derivante dagli investimenti in sicurezza (return on security investment) c’è bisogno di formazione continua, comunicazione, sensibilizzazione, affinché la sicurezza e la protezione dei dati personali possano trovare spazio nella cultura organizzativa, andando oltre le norme giuridiche.
Per contenuti come questo e su tanti altri temi, Iscriviti alla nostra Newsletter!!
![]()

L’impatto dell’intelligenza artificiale (IA) sul mondo del lavoro: nuovi modelli organizzativi e nuovi compiti per l’HR
di Giuliana Cristiano
L’introduzione delle nuove tecnologie nel mondo del lavoro e delle organizzazioni è associabile, tra le altre cose, all’accelerazione tecnologica a cui si aggiunge una conseguente accelerazione dei cambiamenti sociali e dei ritmi di vita. Ci troviamo in quella fase storica che gli esperti hanno ribattezzato “era dell’industria 4.0” in cui le nuove tecnologie, sia nella produzione che nell’erogazione dei servizi, la fanno da padrona[1].
Nel mondo del lavoro, l’utilizzo di tecnologie sempre più sofisticate non sta andando a sostituire solo i processi che prima richiedevano uno sforzo fisico, come la produzione industriale, ma gradualmente sta invadendo anche un settore che fino a poco tempo fa era squisitamente umano, per esempio i processi aziendali di decision making e lo scambio di informazioni. La svolta decisiva in questo senso è avvenuta grazie (o a causa) della diffusione capillare di internet che è diventato una componente essenziale della vita quotidiana della quasi totalità della popolazione attiva mondiale. L’uso massiccio della rete ha determinato, come effetto collaterale, un costante e velocissimo accumulo di dati che, se usati con astuzia, sono uno strumento indispensabile per chi ha necessità di conoscere l’utente ultimo a cui va erogato il servizio o va offerto un prodotto. I big data infatti abbinati all’intelligenza artificiale, permettono il cosiddetto “learning machine” ovvero fanno sì che la macchina (il software) letteralmente impari dai dati che gli vengono messi a disposizione [2].
L’intelligenza artificiale d’altronde non è altro che un ramo dell’informatica, nato nel 1956, che permette di programmare le macchine affinché possano avere caratteristiche cognitive tipicamente umane [3]. L’IA ha un impatto decisivo su diversi livelli, da quello individuale a quello della società. Gli stessi modelli organizzativi hanno subito e subiranno notevoli cambiamenti: le principali sfide da affrontare sono legate alla necessità di acquisire sempre maggiori competenze da parte del personale per il suo utilizzo, capacità quindi di affrontare gli eventuali problemi tecnologici, la necessità di un continuo controllo e il bisogno di fiducia, nonché una ridefinizione della life-work balance. I rischi principali per i lavoratori e le aziende si traducono nella riduzione della privacy, nella possibilità di sviluppare una dipendenza da queste tecnologie e un forte stress lavoro correlato che potrebbe sfociare addirittura nel burnout. I vantaggi però, se l’IA viene usata bene, sono notevoli, in quanto si riducono i costi, vi sono maggiori e migliori feedback sul lavoro da parte della macchina, vi è un miglioramento della qualità dei servizi e prodotti offerti, e se si agisce adeguatamente sulla pianificazione dello smart working, va ad avere risvolti positivi anche sella qualità della vita dei dipendenti. Nonostante alcuni studi tra il 2016 e il 2017 stimarono una sostituzione della manodopera umana con quella artificiale che andava dal 10%[4] al 47%[5], dati molto più recenti hanno dimostrato che la cultura aziendale e l’intelligenza artificiale sono due aspetti organizzativi che si influenzano reciprocamente, tanto che è stato sviluppato un modello detto “CUE” (Culture-Use-Effectiveness Dynamic)che dimostra quanto la cultura migliora l’uso dell’IA che a sua volta migliora i rapporti del team. Questo circolo determina più efficienza e alte prestazioni. Traendo le somme, se utilizzata con astuzia e senza pregiudizio, l’intelligenza artificiale può essere una potente arma verso l’innovazione e il successo dell’azienda sia dal punto di vista produttivo che di benessere del lavoratore[6].
In questo contesto il lavoro degli HR è molto interessante in quanto oltre ad occuparsi della condizione di benessere del lavoratore già assunto, di cui abbiamo parlato poc’anzi, si occupano di acquisizione di nuovi profili. Se fino a qualche anno fa, il recruiter doveva scegliere tra una vasta gamma di offerenti che si proponevano attivamente, oggi, anche grazie alle nuove tecnologie, la cultura del lavoro è cambiata al punto che il potenziale lavoratore è fondamentalmente passivo, carica il suo cv su piattaforme ad hoc e aspetta che sia l’azienda a proporsi. L’HR, quindi, può lasciare l’onere dello screening al software per dedicarsi ad un’attività più lungimirante: la talent acquisition, cioè non semplicemente il processo di ricerca di un lavoratore, ma la ricerca del “talento” adatto all’azienda non soltanto nella risoluzione del problema odierno, ma anche in visione dell’evoluzione dell’azienda stessa e dei suoi problemi a lungo termine[7].
Anche per il recruiting però bisogna agire con cautela: sono diversi, infatti, i casi in cui l’utilizzo dell’IA ha avuto esiti negativi sull’azienda, in particolare un esempio clamoroso è stato quello della grande multinazionale Amazon che a partire dal 2014 ha iniziato ad utilizzare un software per la selezione dei nuovi dipendenti da assumere. A questo software “era stato insegnato” a selezionare i candidati basandosi sui dati estrapolati dei curriculum di dipendenti assunti nei 10 anni precedenti, prevalentemente uomini: si arrivò al punto che la macchina aveva imparato che assumere uomini fosse meglio prediligendo CV con parole come: “eseguito” o “acquisito” tipiche degli ingegneri maschi e scartando quelli in cui c’era scritto “delle donne” o simili. Il software era sessista. Nonostante diversi accorgimenti la situazione non migliorò così il progetto fallì nel 2017[8], lasciando un insegnamento che almeno per ora non può essere ignorato: quando si tratta di scelte sul versante etico e morale, l’uomo ha e deve avere ancora la meglio sulla macchina.
[1] Falcone, R., Capirci, O., Lucidi, F., Zoccolotti, P., Prospettive di intelligenza artificiale: mente, lavoro e società nel mondo del machine learning, in “Giornale italiano di psicologia”, n.1, pp.43-68, 2018.
[2] Ibidem
[3] www.Intelligenzaartificiale.it
[4] Arntz M.T., Gregory T., Zierahn U., The Risk Of Automation For Jobs In Oecd Countries: A Comparative Analysis, in “OECD Social, Employment And Migration Working Papers”, n. 189, 2016.
[5] Frey C.B., Osborne M.A, The Future Of Employment: How Susceptible Are Jobs To Computerization?, in “Technological Forecasting And Social Change”, n. 114, pp. 254-280, 2017.
[6] Ransbotham, S., Candelon, F., Kiron, D., LaFountain, B., Khodabandeh, S., The Cultural Benefits of Artificial Intelligence in the Enterprise, in “MIT Sloan Management Review and Boston Consulting Group”, novembre 2021.
[7] Alashmawy, A., Yazdanifard, R., A Review of the Role of Marketing in Recruitment and Talent Acquisition, in “International Journal of Management, Accounting and Economics”, n. 7, pp. 569-581, 2019.
[8] De Casco A. F., Amazon e l’intelligenza artificiale sessista: non assumeva donne, in “Corriere della Sera – Tecnologia”, 10 ottobre 2018 online: https://www.corriere.it/tecnologia/18_ottobre_10/amazon-intelligenza-artificiale-sessista-non-assumeva-donne-4de90542-cc89-11e8-a06b-75759bb4ca39.shtml
Per contenuti come questo e su tanti altri temi, Iscriviti alla nostra Newsletter!!
Giuliana Cristiano
 Dottoressa in Psicologia applicata ai contesti istituzionali
Dottoressa in Psicologia applicata ai contesti istituzionali
Psicologa Tirocinante in Selefor srl

Dall’idea al prodotto finale: l’uso intelligente dei big data
Di Giuliana Cristiano
Eric Ries nel 2012 definì la startup come “un’istituzione umana studiata per creare nuovi prodotti e servizi in condizioni di estrema incertezza”. Seppur con questo termine si va ad inquadrare una impresa allo stato nascente (in Italia con meno di cinque anni), lo startupping deve essere considerato più una filosofia imprenditoriale dedita alla continua innovazione e trasformazione, in cui quindi l’uso della tecnologia a proprio vantaggio ne è l’essenza[1]. L’imprenditore, in questo caso spesso definito con l’anglicismo “founder”, è un individuo ambizioso e consapevole che seppur stia rischiando investendo una somma di denaro più o meno ingente sulla propria idea, lo sta facendo con lo scopo di apportare un cambiamento prima alla propria realtà e poi a quella globale[2].
La startup, quindi, paradossalmente più che un fine imprenditoriale, potrebbe essere concepita come un mezzo attraverso cui permettere il cambiamento.
È importante tener presente che innovare non significa solo inventare qualcosa di nuovo, ma anche analizzare l’esistente e modificarlo per renderlo accessibile ad altri[3]. Il punto di forza sta nell’essere in grado di osservare il mondo ragionando fuori dagli schemi evitando di cadere nella cosiddetta doppia opacità: non vediamo altre alternative alla realtà e non ci accorgiamo di non vederle[4].
Ma quindi oggi nel pieno della nuova era industriale in cui la trasformazione digitale la fa da padrona, come si può superare tale opacità e rendere la realtà più “trasparente”?
I big data sembrano essere l’arma vincente e la risposta a questo quesito, in quanto permettono una perenne innovazione e garantiscono la competitività sul mercato[5]. Assumere un modello organizzativo che non contempli l’uso di questi dati con il passare del tempo potrebbe diventare rischioso in quanto le aziende potrebbero gradualmente perdere terreno e addirittura fallire[6].
Prima di approfondire è necessario dare una definizione di “big data”: con questo termine si intende un insieme molto vasto di dati derivanti sia dalle attività concrete burocratiche, legislative, economiche e di pianificazione, sia un accumulo spontaneo di informazioni derivanti dall’uso sempre più consistente di internet in cui vi è un perenne scambio di informazioni[7] spesso anche molto personali come preferenze, stile di vita, ambizioni e aspettative.
Gli imprenditori, dunque, devono avere nel team qualcuno che sappia maneggiare con abilità quest’arma in particolar modo tenendo in considerazione l’estremo potere dei social su cui ognuno riversa la propria vita. Capire quali sono i gusti, le preferenze, lo stile di vita, le ambizioni e i valori del costumer, permette di vendere meglio e di più e quindi garantisce non solo la sopravvivenza dell’impresa e il suo successo, ma anche la soddisfazione del cliente.
D’altronde lo stesso Ries, nel 2012, propose di “uscire dal palazzo” cioè incontrare i consumatori e capirne le esigenze sviluppando un prodotto che sia in linea con le stesse[8].
I big data però possono avere anche dei risvolti negativi in quanto la quantità, la velocità di accumulo e la varietà degli stessi, potrebbe generare confusione e innescare bias “di conferma”, problemi di comunicazione e illusione di controllo, ma utilizzando il metodo lean startup ciò potrebbe essere arginato in quanto esso si fonda sulla perenne verifica “scientifica” delle idee e delle ipotesi manageriali. Questo processo è decisamente funzionale soprattutto per quelle realtà organizzative con alti livelli di incertezza tecnologica come le startup o in generale le aziende che puntano all’innovazione[9].
Traendo le somme il processo circolare che conduce allo sviluppo e permette costante innovazione nonché quindi il successo dell’impresa, è rappresentabile come una sequenza input-output:
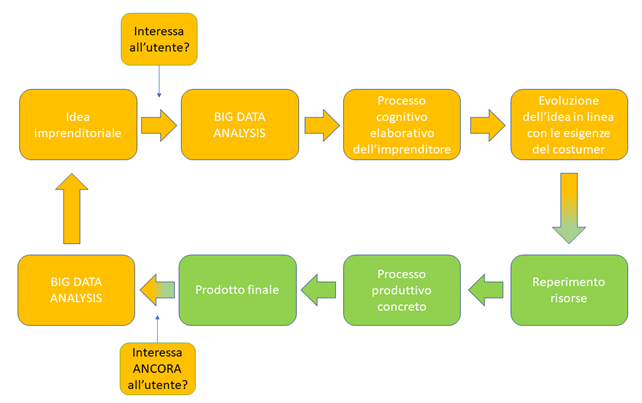
[1] Ries, E., La startup way, Franco Angeli Editore, Milano 2017.
[2] Schumpeter, J. A., Teoria dello sviluppo economico, Milano, ETAS 2002.
[3] Ries, E., Partire leggeri: il metodo lean startup, Rizzoli, Milano, 2012.
[4] Ota de Leonardis, Istituzioni, Carocci Editore, Roma 2001.
[5] Behl, A., Antecedents to firm performance and competitiveness using the lens of big data analytics: a cross-cultural study, in “Management Decision”, n.2, 2022, pp. 368-398.
[6] Nuccio M, Guerzoni M., Big data: Hell or heaven? Digital platforms and market power in the data-driven economy, in “Competition & Change”. N.3, 2019, pp.312-328.
[7] Aragona, B., Big data o data that are getting bigger?. In “Sociologia e ricerca sociale” n. 109, 2016, pp. 42-53.
[8] Ries, E., Partire leggeri: il metodo lean startup, cit.
[9] Seggie, S. H., Soyer, E., & Pauwels, K. H., Combining big data and lean startup methods for business model evolution, in “AMS Review”, n.3, 2017, pp. 154-169.
Per contenuti come questo e su tanti altri temi, Iscriviti alla nostra Newsletter!!
Giuliana Cristiano
Dottoressa in Psicologia applicata ai contesti istituzionali
Psicologa tirocinante in Selefor srl

IL GARANTE PRIVACY SANZIONA CLEARVIEW
A cura di Redazione Selefor CReFIS
Il Garante per la protezione dei dati personali, dopo una complessa istruttoria ha inflitto una sanzione di 20 milioni di euro alla Società statunitense Clearview AI Inc. fornitrice di servizi di riconoscimento facciale. Tali servizi consistono in un monitoraggio del comportamento di persone che si trovano nell’Unione europea compreso il territorio dello Stato membro italiano. Sotto questo aspetto, il controllo del comportamento si caratterizza per la raccolta di immagini, effettuata attraverso tecniche di web scraping, da social network, blog e, in genere, da siti web in cui sono presenti foto pubblicamente accessibili, ma anche video resi disponibili da social media (es., Youtube). Le immagini raccolte vengono elaborate da Clearview con tecniche biometriche al fine di estrarre le caratteristiche identificative trasformate in “rappresentazioni vettoriali” (modelli biometrici).
La Società – che possiede un database di oltre 10 miliardi di immagini di volti di persone di tutto il mondo, estratte da internet – offre pertanto un servizio che, avvalendosi di sistemi di intelligenza artificiale, consente la creazione di profili biometrici ricavati dalle immagini integrati da altre informazioni (metadati), come titolo e geolocalizzazione della foto, pagina web di pubblicazione.
Dall’istruttoria del Garante, attivata anche a seguito di reclami e segnalazioni, è emerso che l’attività di Clearview soddisfa entrambi i presupposti di applicabilità dell’art. 3.2 del GDPR (c.d. targeting) , e dunque l’applicazione del regolamento a trattamenti di dati personali di interessati che si trovano nell’UE, effettuati da un titolare del trattamento (o da un responsabile del trattamento) che non è stabilito nell’Unione (come nel caso di Clearview).
In relazione all’applicabilità dell’art. 3.2, ai sensi dell’art. 27 del GDPR la Società, nel ruolo di titolare del trattamento, avrebbe dovuto designare, mediante mandato scritto, un rappresentante nel territorio dell’Unione europea, incaricandolo come interlocutore, in aggiunta o in sostituzione di Clearview, in particolare delle autorità di controllo e degli interessati, per tutte le questioni riguardanti il trattamento.
Le risultanze istruttorie hanno altresì rivelato che i dati personali detenuti dalla società – dati comuni, biometrici e di geolocalizzazione – sono trattati in assenza di un’adeguata base giuridica che, alla luce delle caratteristiche del trattamento, del contesto in cui si svolge e della finalità (la libera iniziativa economica), va individuata nel consenso degli interessati, dovendosi escludere che il legittimo interesse della Società legato alla predetta finalità economica possa prevalere rispetto ai diritti e alle libertà degli interessati, in particolare al diritto alla riservatezza – messo in discussione da un trattamento particolarmente intrusivo nella sfera privata degli interessati – e al diritto alla non discriminazione insiti in un trattamento come quello effettuato da Clearview.
L’attività di Clearview AI, pertanto, si pone in violazione delle libertà degli interessati, tra cui la tutela della riservatezza e il diritto a non essere discriminati.
La società ha, inoltre, violato alcuni princìpi generali del GDPR, segnatamente i princìpi di liceità, correttezza e trasparenza (art. 5.1.a), GDPR), non avendo adeguatamente informato gli interessati, di limitazione delle finalità del trattamento (art. 5.1.b), GDPR), avendo utilizzato i dati degli interessati per scopi diversi rispetto a quelli per i quali erano stati pubblicati online (non ravvisandosi una “ragionevole aspettativa”, da parte degli interessati, di un utilizzo delle loro immagini per finalità di riconoscimento facciale, per giunta da parte di una piattaforma privata, non stabilita nell’Unione e della cui esistenza ed attività gli interessati sono ignari), e di limitazione della conservazione, non avendo stabilito i tempi di conservazione dei dati.
Alla luce delle violazioni riscontrate, il Garante ha comminato a Clearview AI una sanzione amministrativa di 20 milioni di euro. L’Autorità ha, inoltre, ordinato alla società di cancellare i dati relativi a persone che si trovano in Italia e ne ha vietato l’ulteriore raccolta e trattamento attraverso il suo sistema di riconoscimento facciale. Il Garante ha infine imposto a Clearview AI di designare un rappresentante nel territorio dell’Unione europea che possa svolgere le funzioni di interlocutore, al fine di agevolare l’esercizio dei diritti degli interessati.
Cfr. GARANTE PER LA PROTEZIONE DEI DATI PERSONALI, Provv. n. 50/2022, Ordinanza ingiunzione nei confronti di Clearview AI, in Registro dei provvedimenti, 10 febbraio 2022, https://www.garanteprivacy.it
Cfr. EDPB, Liee guida 3/2018 sull’ambito di applicazione territoriale del RGPD (articolo 3), 12 novembre 2019.
Per contenuti come questo e su tanti altri temi, Iscriviti alla nostra Newsletter!!
![]()

VERSO UNA DATA “DRIVEN ECONOMY”
Articolo a cura di Redazione Selefor CReFIS
Nella prospettiva economica l’approccio data driven significa valorizzare i dati alla stregua di fattori produttivi o, più in generale, fattori dell’attività economica (produzione, commercio all’ingrosso, commercio al dettaglio, consumo).
In questa prospettiva, le aziende data driven affiancano ai processi sottostanti le attività economiche processi elaborativi – trattamenti di dati – per assumere decisioni informate, basate su fatti oggettivi e non su sensazioni personali.
La trasformazione in data driven company non può dunque avvenire con la sola tecnologia, ma con un percorso di change management in grado di portare la cultura del dato a tutti i livelli aziendali. Oggi i CEO e i manager hanno bisogno di informazioni che li aiutino a capire cosa riserva loro il futuro. Avere a disposizione dati corretti, freschi e rilevati con frequenza è fondamentale. In un mondo così veloce, non basta rivolgere l’attenzione al passato, all’analisi di metriche e KPI basati su serie storiche, alla generazione di statistiche e report a consuntivo per effettuare analisi dei dati sui comportamenti degli utenti o per individuare problemi tecnici o eventi critici.
Pensiamo ad esempio alla gestione in tempo reale di macchinari industriali connessi per la manutenzione predittiva, applicata nel caso dell’industria 4.0, o alle transazioni finanziarie e alle assicurazioni, dove l’analisi dei dati serve a individuare le frodi o, ancora, al marketing, dove è necessario ormai anticipare i comportamenti del consumatore conoscendo i suoi gusti.
Un esempio di eccellenza è Spotify, che, con il suo sistema di suggerimento dei brani basato sull’analisi delle preferenze, è una delle aziende più note per avere investito notevoli risorse nel data driven decision making.
Per contenuti come questo e su tanti altri temi, Iscriviti alla nostra Newsletter!!
![]()

IL CONTROLLO DELLA FILIERA DEI TRATTAMENTI
di Giovanni Crea
L’affidamento all’esterno di trattamenti di dati personali genera una ‘filiera’ di attività più o meno complessa in relazione al numero dei soggetti partecipanti (responsabili e sub-responsabili del trattamento, altri titolari del trattamento) e alla sua estensione geografica (tanto più se tale estensione implica trasferimenti di dati oltre i confini dell’UE).
I casi “B&T-Dorelan”, “Enel Energia” e “Google analytics vs. DSB” ci raccontano di situazioni che danno luogo a filiere di trattamenti la cui compliance alla disciplina del trattamento dei dati personali – quale che sia la loro complessità – ricade comunque sotto la “responsabilità generale” del titolare del trattamento. Sotto questo aspetto, va osservato come, in virtù del princìpio di responsabilizzazione di cui all’art. 5.2, GDPR e delle implicazioni di responsabilità previste all’art. 24, GDPR, il titolare del trattamento sia il centro di imputazione delle scelte effettuate con riguardo alle misure tecniche e organizzative in una prospettiva di compliance, a cui compete anche la dimostrazione (accountability) di tale conformità. Il controllo della filiera dei trattamenti va pertanto ricondotto al quadro delle predette scelte.
L’esternalizzazione dei trattamenti, dunque, implica il controllo della filiera che essa genera; controllo che, alla luce del citato princìpio della responsabilità generale, va realizzato attraverso misure tecniche e organizzative (modelli organizzativi) che consentano al titolare del trattamento di gestire sia le attività svolte dai responsabili del trattamento (compresi i sub-responsabili) per le proprie finalità sia l’acquisizione di dati da distinti titolari del trattamento (fornitori di banche dati, list provider).
L’assenza del controllo ha ricadute sugli interessati con riguardo (i) alle informazioni che questi dovrebbero ricevere ai sensi degli artt. 13 e 14, GDPR, (ii) all’azionabilità dei loro diritti previsti agli artt. 15-22, GDPR, (iii) alla possibilità di revoca del consenso (là dove ricorre questa base giuridica), (iv) alle violazioni dei loro dati (data breach) che potrebbero verificarsi lungo la filiera. Tali ricadute configurano altrettante violazioni della disciplina del trattamento dei dati personali ascrivibili al titolare del trattamento.
Al riguardo, nelle vicende “Enel Energia” e “B&T-Dorelan” il Garante ha contestato, tra gli altri profili, una carenza informativa con riguardo all’individuazione dei soggetti destinatari dei dati personali, nonché l’impossibilità per gli interessati di esercitare i propri diritti, in particolare i diritti di accesso e opposizione al trattamento. Profili, questi, che sono apparsi legati alla mancata qualificazione dei ruoli e alla numerosità dei soggetti coinvolti nel trattamento, e per i quali non è valsa la dichiarazione della società Enel Energia dell’impossibilità del controllo di soggetti che si inseriscono abusivamente nella propria filiera dei trattamenti né, tanto meno, quella di B&T di ritenersi estranea al ruolo di titolare del trattamento.
L’esperienza del telemarketing – vale a dire la promozione e commercializzazione di beni attraverso servizi di comunicazione elettronica – ha messo in luce come, su tale versante, le relative attività generano filiere di trattamenti che, se non controllate dai titolari del trattamento, favoriscono la proliferazione, da un lato, di list provider – le cui procedure di raccolta dei consensi per la comunicazione dei dati di contatto agli stessi titolari o ai loro responsabili del trattamento (call center) non sono note – e, dall’altro, di operatori che si inseriscono in modo abusivo lungo la catena fino a individuare una porta di accesso ai sistemi informatici del titolare deputati all’attivazione delle offerte e dei servizi, attraverso la quale tali figure veicolano i risultati delle proprie attività.
Nella prospettiva del garante, dunque, la mancanza di un modello organizzativo per il controllo e la gestione della filiera dei trattamenti è la causa del fenomeno della formazione di un ‘sottobosco’ di attività svolte da soggetti che, sfruttando questa falla organizzativa, generano un allarme sociale dovuto a una diffusa perdita di riservatezza che in alcuni casi potrebbe anche costituire oggetto di attenzione da parte della criminalità. Nel caso Vodafone del 12 novembre 2020 il Garante per la protezione dei dati personali ha contestato alla società di telecomunicazioni di non aver implementato un sistema di controllo della filiera fin dal primo contatto dell’interessato idoneo a escludere che da chiamate promozionali illecite (effettuate sulla base di un utilizzo illecito di dati di contatto) possano seguire attivazioni di servizi o sottoscrizioni di contratti che implicano trattamenti su dati inutilizzabili ai sensi dell’art. 2-decies, d.lgs. 196/2003.
Per contenuti come questo e su tanti altri temi, Iscriviti alla nostra Newsletter!!
Giovanni Crea

Direttore del Centro di Ricerca e Formazione Integrata Selefor, responsabile scientifico e Presidente del Comitato Tecnico-Scientifico con delega Data Protection.
Economista, è professore incaricato di “Economia Aziendale e Processi di amministrazione del lavoro” presso l’Università Europea di Roma, dal 2014 insegna la materia di “Protezione dei dati personali” presso Master Universitari e Corsi specialistici.